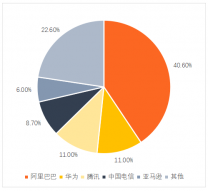
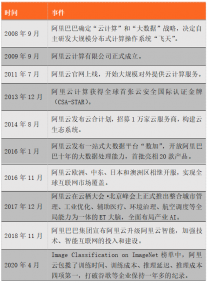
那么这意味着什么?
人们可以预期,Hadoop在应用程序架构层面所做的工作也将在全球范围内发生:庞大的数据集将成为使数据的逻辑具有意义的吸引力。而那些庞大的数据集将会被吸引到一起。
举个例子:许多公司现在都在努力减少移动数据的需求。因此,在物联网领域有很多关于边缘计算的讨论:本地处理传感器和其他物联网设备的数据。当然,这也意味着处理过程也必须是本地化的,可以放心地假设一下,企业不会在一组传感器中拥有同样的计算能力,而不是在大分析中可以做到的设置。或者:也许自主驾驶汽车的数据很可能不会再采用Hadoop集群,而可以通过这种方式来最小化数据流量,但以计算量为代价。
这个问题还有另一个解决方案:与数据中心结合在一起。数据中心托管提供商提供的服务正在崛起。他们提供具有优化内部流量功能的大型数据中心,云计算提供商和大型云用户的服务器都在一起。从逻辑上讲,用户的业务可能在云端,但实际上与云计算服务提供商在同一处所。
企业不仅想在AWS或Azure上运行其逻辑数据,也想在数据中心这样做,企业也有自己的私有数据湖,所以所有的数据都在本地处理,数据聚合也在本地。但是数据中心托管模式是另一种可能的解决方案,用于解决因数据呈指数级增长而带来的带宽和延迟问题。
情况可能不像那两个调查报告描述的那样可怕。例如,所有数据的实际平均波动率最终将非常低。另一方面,企业不希望在陈旧的数据上运行分析。但是可以得出一个结论:简单地假设企业可以将其工作负载分配给不同的云提供商是有风险的,尤其是如果同时处理的数据量(如果企业都想把他们自己的数据与来自Twitter、Facebook的数据流结合起来,那么更不用说这些组合产生了各种各样的新数据流)。
因此,企业对数据和处理的位置做出良好的战略设计决策是成功的关键。