5.数据脱敏技术的实现
通过程序对敏感数据的自动识别,能够自动识别的敏感字段包括:电话号码,姓名、地址、邮件、身份证号、银行卡号等。识别数据的方法使用到了正则表达式和关键字识别,身份证号、邮箱、电话号码都可以采用正则表达式的方法来识别。电话号码识别,正则表达式((((010)|(0[2-9]d{1,2}))[-s]?)[1-9]d{6,7}$)|((+?0?86-?)?1[3|4|5|7|8][0-9]d{8}$)银行卡号识别,正则表达式(([13-79]d{3})|(2[1-9]d{2})|(20[3-9]d)|(8[01-79]d{2}))s?d{4}s?d{4}s?d{4}(s?d{3})?$身份证号识别,正则表达式 [1-9]d{5}(19|20)d{9}[0-9Xx]$邮箱识别,正则表达式 [a-zA-Z0-9_%+-]{1,}@[a-zA-Z0-9-]{1,}.[a-zA-Z]{2,4}$姓名、地址采用关键字识别方法,例如姓名中内置三百个姓来做姓名的自动识别,地址中通过街道、区、市、县、村、栋等关键字来匹配。这里我们使用了Python来实现敏感数据的扫描,只需要配置数据库连接参数,就能自动进行全库扫描。在进行全库扫描时为了防止占用的资源会比较多,通常会设置自动扫描参数,参数包括扫描最大数据量、采样数据量等,当表的数据量少于最大数据量这个阀值时,会进行全表扫描配置。另外一个参数是采样数据量,当表的数据量超过最大数据量时,会对表的数据进行采样,选取其中的一定量的数据(采样数据量)进行扫描。扫描的同时需要对扫描到的敏感数据记录下来。记录的信息包括:数据库IP、数据库用户、数据库、扫描表、扫描字段、敏感数据内容、敏感数据类型、敏感数据率等。
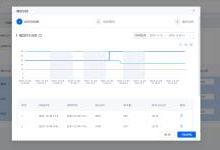
数据动态脱敏使用ShardingSphere分布式治理子功能模块。它通过对用户输入的SQL进行解析,并依据用户提供的脱敏配置对SQL进行改写,从而实现对原文数据进行加密,并将原文数据(可选)及密文数据同时存储到底层数据库。在用户查询数据时,它又从数据库中取出密文数据,并对其解密,最终将解密后的原始数据返回给用户。Apache ShardingSphere分布式数据库中间件屏蔽了数据脱敏过程,让用户无需关注数据脱敏的实现细节,像使用普通数据那样使用脱敏数据。先看下动态数据脱敏的的实现原理:

在使用 ShardingSphere-JDBC进行动态脱敏配置时,有几项关键的脱敏规则配置。1)数据源配置,可以使用了Druid来做数据源配置,配置多个数据源。ShardingSphere-JDBC可以兼容的数据库连接池比较多,类似于DBCP,C3P0,BoneCP,Druid,HikariCP都可以用来和shardingsphere配合使用。采用Druid做为数据库连接池需要设置驱动、数据库连接地址、用户名、密码即可,filter参数为Druid连接池参数,用于配置监控sql语句的执行。2)加密器配置, ShardingSphere-JDBC内置了AES/MD5两种加密算法。这里采用了AES对称加密算法,当然用户还可以通过实现ShardingSphere提供的接口,自行实现一套加解密算法。3)脱敏表配置,比如要把user表中的用户密码进行加密存储。在脱敏表的列配置中plainColumn对应字段存储密码明文、cipherColumn对应字段存储加密后密码。对应的开发人员使用的是逻辑列pwd,开发人员在进行开发过程中,直接面向pwd进行编程即可,不需要关注是否进行加密和解密问题。下面是开发人员使用的mybatis进行的配置,直接使用的pwd字段进行开发。如下图:

参考资料:1、官网资料2、A project report on“Masquerade - Data Masking Tool”3、Risk Based Security. Data Breach QuickViewReport 2019 Q3 trends. 2019-11.4、 数据脱敏技术发展现状及趋势研究
精选提问:
问1:请问对于图库数据、地理信息数据等非结构化类数据的脱敏,具体的脱敏思路是什么样的,目前有无脱敏的开源工具。
答:图数据库脱敏需还要看应用场景,在分析应用的场景中,数据脱敏一般是在数据加载到图数据之前就已经从生产的数据进行脱敏处理过的了。生产环境图数据库脱敏主要是vertex属性的脱敏,可以参考动态脱敏的技术实现。对图数据库脱敏的开源工具没有进行深入分析过。
问2:如A经B到C,C经D到E,而给我们的关系脱敏后表现为A..B...D..E。类似的这类脱敏如何实现。
答:单独的客户信息,还是有需要进行脱敏处理的。融合关联的得到新信息,比如对客户和订单关联后,分析出客户的购买习惯。需要对客户基本信息、订单基本信息进行脱敏,购买习惯属于分析结果(包含的客户、订单已经脱敏过)不需要在进行脱敏处理。